论文:VBridge: Connecting the Dots Between Features and Data to Explain Healthcare Models
作者:Furui Cheng, Dongyu Liu, Fan Du, Yanna Lin, Alexandra Zytek, Haomin Li, Huamin Qu, and Kalyan Veeramachaneni
发表:VIS, 2021
现在机器学习方法越来越多的使用在电子医疗数据中完成一些临床预测任务,但是模型的透明性和可解释性限制了这些方法在实际中的应用。本文设计了可视分析工具VBridge,来帮助机器学习方法按照实际临床的决策过程进行解释。
introduction
随着电子病历的出现,也有越来越多的机器学习预测模型能够直接利用这些数据来提高临床预测的质量。电子病历包含着一个人的健康信息,有结构化信息也有非结构化的信息。使用电子病历中的这些信息,预测模型可以对一医学数据进行预测,比如剩余住院时间,再次住院的可能性或者院内死亡的概率。
尽管已经有很多的方法来提高模型性能,但现在仍有一些挑战,这些问题大多数和模型的透明性和可解释性相关,尤其是在医学这样规则化并且延误风险的领域中。与此相关的是XAI(axplainable AI)技术,XAI可以帮助阐明黑盒AI模型的工作原理。即便有这样的方法,现在基于机器学习的模型仍然没有广泛的在医学领域使用,通过调研,阻碍XAI技术应用的因素主要有两个。
1:使用XAI的医生通常假设是拥有充足的相关技术知识,其能够理解甚至帮助改善ML模型。但实际经常是一些几乎没有相关背景知识的医生从他们自己的专业视角评估模型,而不是从模型相关的技术视角来改善模型。这种技术和user的隔阂是因为在开发XAI工具时医生本身很少参与到讨论中。结果就是模型的结果通常是纯技术的,医生很难从中获取到具体的解释。
2:医生的工作流中常常需要针对具体病人进行,对不同的病人需要进行针对性的解释。这其中应用比较多的方法是feature contribution,这种方法主要是计算特定的ML特征对结果的贡献,这样可以帮助医生对比自己的诊断结果和模型的预测结果。
除了这两个问题,医生在使用ML工作时还有遇到以下问题。
1:理解ML特征
不是输入模型的每个特征都能按照医生所想的进行解释。例如一个病人的关键指标如术时心率可能会变换为多种ML特征,每个是一个时间段内的聚合特征比如标准差,趋势(Trend)。这样的特征对医生来说可能是不熟悉的或者反直觉的,医生很难对其进行解释
2:和病人的原始病历联系
相比于ML特征,医生对病人的原始病历更加熟悉,所以医生会常常参考这些原始数据进行诊断。但是特征贡献方法只针对ML特征进行解释,不能结合原始病历。
3:和具体证据对齐
简单地用一组数值来表示特征的贡献程度并不能帮助医生评估模型结果的可信程度。医生需要结合 evidence-based medical practice(循证医学实践)来理解特征贡献。这里我们提出使用cohort分析(同期群分析,分组分析),结合医院的记录来提供证据。医生可以把目标病人的特征数值和相似病人群组的病人数据进行比较。
基于以上的挑战本文设计了一个可视分析工具来讲特征解释整合到医生的决策工作流中。作者进行了pilot study,明确了系统的设计需求,并总结了两种工作流模式。本方法使用了SHAP值来产生依据贡献的特征解释同时使用了层级化方法来组织大量特征以便交互。本系统还开发了一个新的可视化,一个可交互的层级特征表,通过一种用户友好的方式把修订后的特征展示给医生。为了练习特征解释,系统使用了Deep Feature Synthesis来创建特征到记录之间的可追踪变换,基于此系统还给出了一个算法来针对非定特征找到最有影响的记录。
本文的主要贡献包括:
总结出了七个设计需求,明确了医生使用ML模型的两种工作流程
设计了一个可视分析系统
进行了两个case study和一次专家访谈
informing design
这里介绍pilot study,设计要求和分析工作流
pilot study
pilot study可以帮助我们理解医生是如何期望带有特征贡献解释的ML模型帮助进行医学决策的,我们进行了如下的pilot study
participants:包含6个来自浙江大学医学院附属儿童医院的医生,2位是心脏病加强监护病房的主治医师,4位心脏病科的实习医生(P1-P6)。P1-3资历比较高,平均有24.5年的工作经验。P4-6平均有10.5年的工作经验
presetting:pilot study基于术后并发症预测的场景。病人们会有不同的术后并发症明其中一些可能是致命的。早期的预测可以帮助医生识别高危病人并选择精心的术后照顾计划。我们在此场景下建立了demo模型。我们和生物医学数据家合作精心选择了一小组特征来训练模型。我们使用SHAP值来显示特征贡献。
process:研究分为两个部分。第一部分进行一对一的半结构,一小时采访。采访中参与者会被提供我们早期系统的低真模型和一些基础的ML概念。收集到反馈后我们形式化设计的初始需求。接下来的几个月开发原型系统。第二部分我们给P2,3,5提供原型系统。他们被要求自由探索系统并完成几个预测任务,然后解释他们的想法,我们基于这个反馈继续修改系统。
设计需求
分为7点。设计三个方面。特征,数据和连接
1 特征:使用层级结构展示特征。根据医生的需求,由于特征条目太多,分级比较清晰
2 特征:提供特征参考值。标准差,趋势这样的聚合数值对医生来说不是很熟悉。应该使用同类群体提供参考数值
3 特征:提供灵活的交互。提供排序和筛选操作
4 数据:提供病人病历的视图。
5 数据:使用参考值展示细节。在展示历史病历时也给出参考值
6 链接:链接特征和病人的记录。
7 链接:高亮某些数值随时间变化的模式,便于找到高风险时期
分析流
我们总结了两个通用的分析流程。
前向分析
分析流程:原始数据 - 特征- -预测结果
医生P1,P2在分析时习惯先浏览病人简历,自己先有一个对结果的假设,然后按照前向流程深入进行分析。
反向分析
和前向相反,这里医生首先查看模型的预测结果和解释,然后逐渐追溯到原始记录上。
预测建模
数据
使用电子病历数据并组织成关系数据库。数据集使用PIC数据集。
测试用例 手术并发症预测
这里使用ML模型预测病人心脏手术后的五种并发症:肺,心脏,心律失常,感染,其他(L,C,A,I,O)一个病人可能有多种术后并发症。
从PIC数据集开始,首先选取了1826个体外循环支持心脏手术的病人,其中25%有术后并发症。从这些数据中我们主要抽取了三种静态特征,demographics,手术信息和诊断结果;三种随时间改变的动态特征, lab tests, surgery vital signs, and chart events 。我们的目标是构建五个独立的二元分类器。
为了模型处理,病历数据需要处理成ML可理解的格式,也就是特征向量。所有病人的特征限量构成特征矩阵。为了获得我们任务上的最好ML模型,我们使用了cardea,一种自动机器学习框架。最终我们获得了五个效果最好的分类器。
特征抽取
如图2A所示,电子病历数据描述为不同的实体,实体之间有reference key链接。在样例测试中,我们确定了六种特征类型,包含静态和动态的。
这里选择surgery(Es)作为目标实体
我们使用Deep feature syntheses(一个自动从关系表中生成特征的算法)来保证病人特征和原始记录之间存在可追溯的联系(R6)。这个算法是一个迭代过程,针对每一个产生的特征,都可以找到一个可追溯的生成路径,因此可以追踪。
特征解释
我们使用SHAP value提供特征层面的解释。但是对于那些随医生来说不是很熟悉的特征解释是不充分的,医生希望具体时间哪段时间的记录和他们感兴趣的特征相关。
针对记录,一个通常的方法是遮挡灵敏度。但是简单的移除一些记录然后看预测结果变化并不是很可行的方法,因为一个病人一般会产生上千条数据,也就是说只删除几条数据对模型整体不会有很大的影响。另一个方法是遮挡后看其他相关特征的变化,当然这也存在着同样的问题。
解决:首先计算记录对相关特征数值的影响,然后确定最具影响的时间段。然后过滤出把相关特征数值改变大(推离平均值)的记录片段。比如考虑脉搏变化,一个医生希望知道那个时间段的记录导致了数值的剧烈变化,而不是整个受影响阶段。
在动态特征上计算记录影响的方法:考虑窗口大小k和一组时序记录E,长度T,结果向量v初始化0向量。我们迭代的替换/遮挡片段t:t+k,然后每一步增加t。遮挡数据可以使用线性数据进行填充。每一个step后重新计算特征数值,然后记录下正当前后的数值变化,变化的比例记录在结果向量中。这样最后v就显示了所有记录的相对影响。
确定最有影响的时间段的方法:计算好向量v,下面找到最有影响的时间段。这里需要我们设定阈值theta,然后使用这个阈值分割出频段。这里使用一个没有统计假设的无参方法。后续系统会给出这个方法的一个新的可视化方案。
VBridge
系统设计
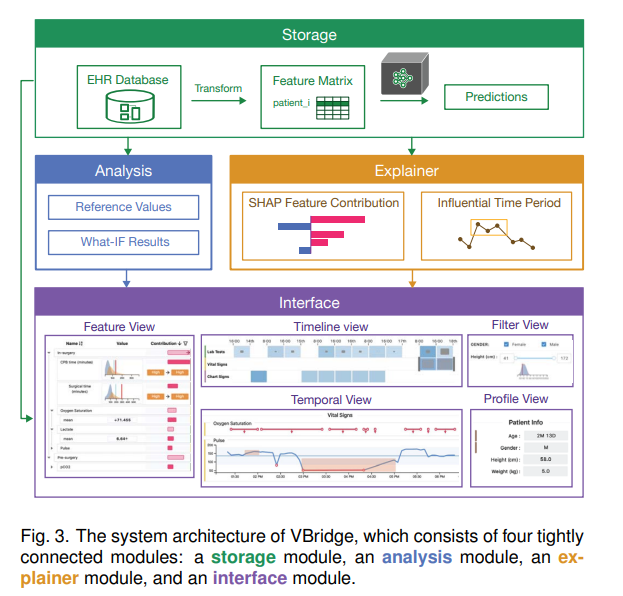
overview
图三展示了主要模块:储存,分析,解释器,界面。
这里我们假设一位医生使用反向分析流程来套就病人术后并发症的危险。
首先选取病人和感兴趣的并发症。(A)五个icon的颜色表示了风险大小。
接下来浏览profile视图。使用filter视图选取一组相似病人作为对照(0)
下面开始探究feature视图,层级地展示了ML特征,包括他们对结果的贡献以及参考数值。为了进一步探究感兴趣的特征,需要在temporal视图中检查特征的原始记录,这个视图展示了病历的时间变化,包含了参考值和影响区间的变化。
如果目标特征的原始记录不充分还可以继续探索timeline视图,选择同时期的其他记录进一步探索。
feature view
允许医生从特征层面探索和理解模型行为。这里的特征进行了分组,首先按照同一个医学数值分组,比如脉搏的平均值方差变化程度分为一组;其次按照出现时间进行分组,包括手术前特征和手术中特征。
层级展示:需求1
满足不同医生的探索需求
同类参考值:需求2
比如选择同年龄群体进行对比对照
假设分析:需求3
医生经常关注一些反常记录,我们的系统把参考值范围外的数值标记为异常。医生会更想关注高贡献的异常数据。比如图4中的手术时间明显过长,实际采访中医生野队这样的case有兴趣,我们提出疑问,如果这个是一个正常值其贡献还会很大吗。
因此这里涉及了以一个基于参考值的假设分析技术,如图4c。我们一次关注一个异常特征,然后对其进行细小改动使其到正常的参考范围中,然后计算并可视化预测结果和特征贡献。图例中贡献减小表明该特征有关键作用。
temporal view
这一部分可视化了一组时间序列,每一个代表一个随时间变化的医学特征比如心率。当医生在特征视图中找到感兴趣的特征后他们可以在该视图中追加相关时间序列进一步分析。
每个时间序列可视化为折线图(5B)半透明蓝色区域和蓝色水平线代表参考范围和参考平均值。这个设计对医生来说比较熟悉。
高亮异常数据和同期病人分析:5B,红色点线代表了异常区域。A是简略显示
高亮有影响的模式:参考值给医生提供了一个可询证的参考但是医生也很好奇ML模型怎么评判某个时间段的影响,我们使用之前的算法找到这些时间片并且高亮他们(5E)C-E是集中针对有重叠情况的可视化可选方案。
timeline view
提供了目标病人的病历视图。这里使用了基于矩阵可视化的方法。这里时间段的方块背景颜色编码了时间的数量,内部方块的占比表明了异常事件的数量。用户可以在这里框选时间段来调整temporal视图显示的内容。
interaction
除了提到过的额外的交互:linking和marking
特征和record的关联:
指的是特征视图和temporal视图之间的链接,可以帮助医生更快的把特征和record联系起来。
marking on record
医生可以把感兴趣的记录元素固定住(pin),与其对应的相关特征就会被着重表表示(thicker bar),使用特征视图的focus开关可以移除医生不感兴趣的特征
Evaluation
两个case,前向和反向,这里介绍一下反向的例子。例子中涉及到很多医学名词和医生自己在分析过程中的评价。
反向
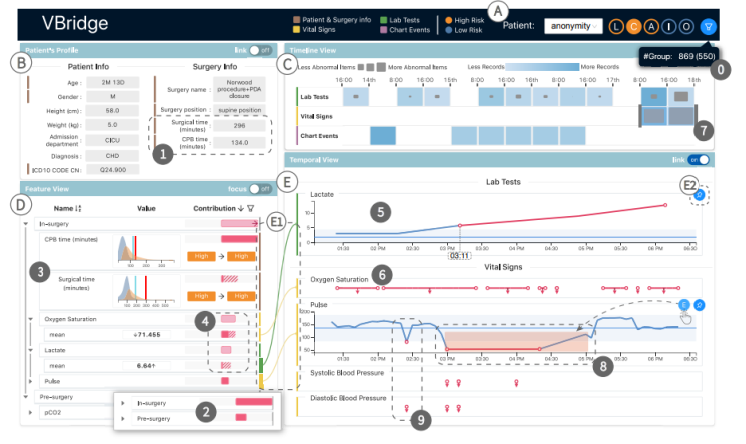
这个例子中我们对医生P5进行了测试,患者是进入CICU的五个月大婴儿。i预测结果显示L,C,A三个并发症的概率比较大,医生对C心脏并发症比较感兴趣。他首先选择了一组相同年龄段的病人作为参考,包含869名病人其中550是健康的。
探索特征层级(R1)
医生首先探索病人建立注意到两个特征,手术时间和CPB时间比一般数值要大,基于此他继续探索特征视图查看特征贡献,在特征层级的顶层,他注意到手术中特征组比手术前特征组有更大的贡献程度,意味着模型主要使用手术中的特征进行了预测。那么接下来医生展开这个层级查看其中的特征,通过排序筛选,他确定了这些特征。
理解特征贡献(R2)
他注意到CPB时间和手术时间是最重要的两个特征并且数值都偏离了正常分布,接下来他想继续了解假设分析的情况,结果发现两个情况下预测结果都没有明显的变化。但是他注意到减少手术时间到正常范围时会显著减少这一个特征的贡献。他认为这个特征对结果贡献很大但是其他因素也很重要所有预测结果并没有显著变化。
接下里医生关注氧气饱和和lactate乳酸盐数值。展开这两项后发现主要来自与均值特征,不是异常偏低就是异常偏高。接下来他通过假设分析得到这两项异常值的确会有重要的影响。
接下里继续探索特征有影响的记录,查看temporal view,医生观察到lactate 水平在手术开始比较正常,但是下午两点之后开始增加,最终在下午三点超过了参考值。但是氧气饱和在整个手术过程都低于参考值。接下来医生希望探究Lactate积累的原因,他假设这是由CPB过程直接导致的,因此他参考timeline 视图然后选择手术中的vital sign作为参考。
仔细观察脉搏记录,他注意到下午三点脉搏降低到一个很低的水平,因此他确认这是CPB时期,这是平人的心肺功能被CPB接管。对比同时期lactate曲线,他拒绝了之前的假设。接下来他关注脉搏在下午两点半左右的突然下降,他在视图中选择explain然后系统高亮出有影响的时间片段,这些片段刚好覆盖了CPB时间段。最终医生结合自己的理解对模型的预测给出肯定。
Discussion
优点:
- 基于参考值的解释
- 特征层级设计
- 使用上下文提供解释
缺点:
- 特征解释。现在系统只支持解释有明确实在意义的特征,如果特征本身就很难理解那其和数据之间的关系也会很复杂。
- 潜在的认知偏见。
- 电子病历数据质量
- 参考值的准确程度
- 可视化scalability
- 扩展到其他病历模型
✉️ zjuvis@cad.zju.edu.cn